Eine Einführung in ADO.NET
Die Bezeichnung ADO.NET für die Datenbankzugriffs-Architektur
von .NET suggeriert Kontinuität. So ein bisschen wie ADO 2.0 oder ADO
2002. .NET wäre aber nicht .NET wenn Microsoft nicht auch hier tiefgreifend
Hand angelegt hätte, so dass am Ende doch fast kein Stein auf dem anderen
geblieben ist. Dieser Beitrag richtet sich sowohl an ADO-Kenner als auch
ADO-Nicht-Kenner und vermittelt ein erstes Basiswissen über die Datenbank-Schnittstelle
in .NET auf dem Stand der Beta 2.
Natürlich sind viele Konzepte, die im Rahmen
von ADO und von ADO-Erweiterungen entwickelt worden sind nach wie vor gültig.
Begriffe wie Provider, Connection, Command tauchen auch in ADO.NET wieder
auf. Andere wie DataSet erinnern zwar an ADO, haben aber eine völlig
neue Bedeutung erhalten. Und dann gibt es noch jede Menge neuer Termini
wie Adapter oder Relation, die man auch als ADO-Veteran
erst einmal in sein Weltbild einordnen muss.
Die Grundidee in ADO.NET ist die unverbundene Datenmenge
(disconnected data set), wie es sie ja auch in ADO und bei den Remote Data
Sets (RDS) schon gibt. Allerdings ist diese Idee in .NET von einem interessanten
Spezialfall zur fundamentalen Architektur-Entscheidung geworden. ADO.NET
in seiner derzeitigen Ausprägung kennt überhaupt keine verbundenen
Datenmengen mehr.
Architektur
Eine Vorstellung vom Aufbau von ADO.NET liefert das
einfache Schichtenmodell in Bild 1.
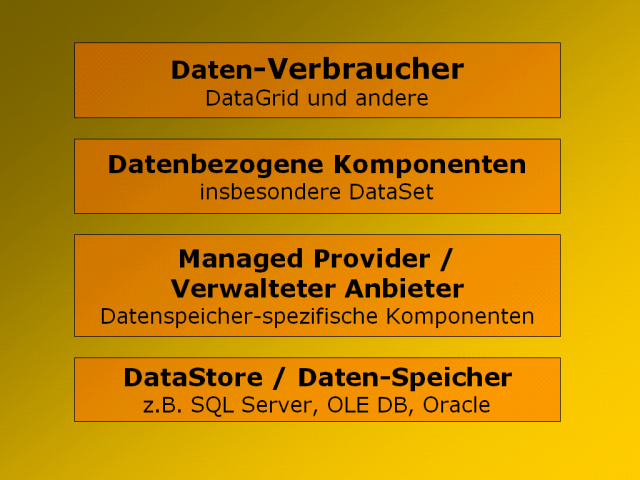
Bild 1: Die Kernfunktionalität von ADO.NET
spaltet sich in einen Datenspeicher-abhängigen Teil (Managed Provider)
und einen unabhängigen Teil (Daten-bezogene Komponenten).
Auf der untersten Schicht findet man den Datenspeicher.
Dies kann natürlich ein Datenbank-Server (gerne SQL Server) oder eine
OLE DB Datenquelle (Jet-Engine oder wie auch immer das derzeit genannt werden
soll) sein, aber auch jede beliebige relationale oder nicht-relationale
Datensammlung. Der Datenspeicher ist Hersteller-spezifisch und im Regelfall
unabhängig von .NET.
Die Brücke bildet der Managed Provider,
der auf dem Datenspeicher aufsetzt und den Anschluss an das .NET-Framework
schafft. Wie überall in .NET bedeutet die Eigenschaft Managed
auch hier, dass der Provider in der gemeinsamen Laufzeitumgebung (CLR) läuft.
Es handelt sich also um eine Reihe von .NET-Komponenten, auf die später
noch genauer eingegangen wird. Der Managed Provider umfasst die Verbindung
zur Datenquelle, das Ausführen von (SQL-) Kommandos, und den Transport
der Daten zu und von der nächstfolgenden Schicht, der Datenmenge (Data
Set).
Unverbundene Datenmengen
Die grundlegende Entscheidung für das unverbundene
Modell in ADO.NET bedeutet an dieser Stelle, dass der Datentransport gebündelt
und explizit abläuft und nicht kontinuierlich und automatisch wie bei
einer verbundenen Datenmenge. Beim Ausführen eines SELECT-Kommandos
wird eine Verbindung zur Datenquelle hergestellt, die Abfrage abgesetzt,
die Ergebnismenge komplett zum Client transportiert und die Verbindung dann
wieder geschlossen. Das Ändern von Daten geschieht ganz analog: Verbindung öffnen,
eine Reihe von UPDATEs, INSERTs und DELETEs absetzen, Verbindung wieder
schließen.
Daraus wird klar, dass an die dritte Schicht des Modells
hohe Anforderungen gestellt werden müssen. Die Datenmenge verhält
sich für den Anwender wie eine eigenständige kleine "offline-"
Datenbank. Sie speichert die von der Datenquelle abgefragten Informationen,
bietet sie zur Weiterverarbeitung (z.B. in Steuerelementen) an und registriert
und hält Änderungen bis zur Aktualisierung in der Datenquelle.
Auf der obersten Schicht sitzen alle Komponenten für
die Anzeige und Bearbeitung der in der Datenmenge gespeicherten Informationen.
Das Datengitter (Data Grid) ist der klassische Vertreter für diese
Gattung von Komponenten. Aber natürlich gehören auch alle anderen
Steuerelemente mit Datenanschluss dazu und überhaupt alle Komponenten,
die Daten aus Data Sets auslesen und/oder manipulieren.
Komponenten
Nach diesem Überblick geht es jetzt mehr in die
Tiefe und das bedeutet Komponenten, Schnittstellen und Code. Als Programmiersprache
für die Beispiele wird C# verwendet, weil das zum einen die .NET-Sprache
schlechthin ist und zum anderen sowohl für C++-Programmierer als auch
für Visual Basic-Programmierer verständlich sein dürfte.
Das Objektmodell in Bild 2 zeigt den Aufbau eines
Managed Providers.
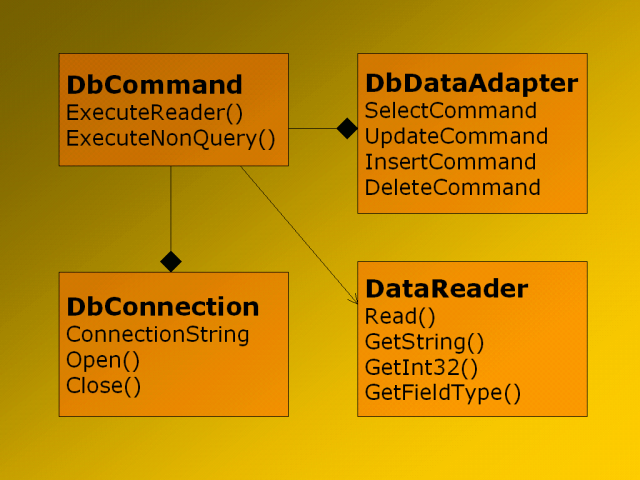
Bild 2: Ein Managed Provider besteht aus Komponenten
für Connection, Command, Reader und Adapter.
.NET arbeitet wie COM sehr stark mit Schnittstellen,
so dass in diesem Objektmodell hauptsächlich Beziehungen zwischen Interfaces
dargestellt sind. In der Beta 2 sind zwei Managed Provider für SQL
Server und OLE DB enthalten, die jeweils diese Schnittstellen und damit
auch die Beziehungen zwischen ihnen implementieren. Das Objektmodell stellt
somit allgemeine Beziehungen dar, die für jeden beliebigen Managed
Provider gelten. Alle aufgeführten Schnittstellen sind im Namensraum
System.Data deklariert.
Mit IDbConnection und IDbCommand
enthält ein Managed Provider zwei von ADO her bekannte Komponenten.
IDbConnection enthält wie zu erwarten eine Eigenschaft für
den ConnectionString und den aktuellen Zustand (offen/geschlossen)
sowie Methoden Open und Close. Zumindest hier gibt es
keinen großen Umlern-Bedarf. Das gleiche gilt für IDbCommand.
Es enthält einen Verweis auf die zugehörige Datenbank-Verbindung
und einen String, der das auszuführende Kommando aufnimmt. Im Unterschied
zu ADO, muss in ADO.NET jede Ausführung über ein DbCommand-Objekt
ablaufen, die direkte Ausführung z.B. über die Verbindung selbst
wird nicht mehr unterstützt.
Die IDbCommand-Schnittstelle enthält zwei Methoden
zum Ausführen von Befehlen. Mit ExecuteNonQuery() wird ein UPDATE,
INSERT oder DELETE ausgeführt, mit anderen Worten jedes Kommando, das
keine Ergebnis-Menge zurückliefert. Wenn ein SELECT-Statement ausgeführt
wird oder ein anderer Befehl, der Daten zurückliefert (ADO.NET ist
ja nicht auf SQL beschränkt), benutzt man ExecuteReader() und erhält
eine von DataReader abgeleitete Klasse zurück, die den Zugriff auf
die Ergebnismenge erlaubt.
Daten auslesen
Der DataReader repräsentiert einen unidirektionalen,
nur-Lesen Zugriff auf die Ergebnismenge in Form eines Server-seitigen Cursors.
Das bedeutet, die Daten werden direkt vom Server geholt und erfordern deshalb
eine stehende Datenbank-Verbindung. Die Methode Read() liefert
bei jedem Aufruf den folgenden Datensatz in der Ergebnismenge, ohne eine
Möglichkeit, wieder auf den vorherigen oder den ersten Datensatz zurückzugehen.
Durch diese Einschränkungen wird eine hoch-performante Implementierung
des Cursors möglich. Außerdem soll die Dauer der Datenbankverbindung
ja möglichst kurz gehalten werden. Die Verarbeitung der Daten geschieht
dann offline im Data Set.
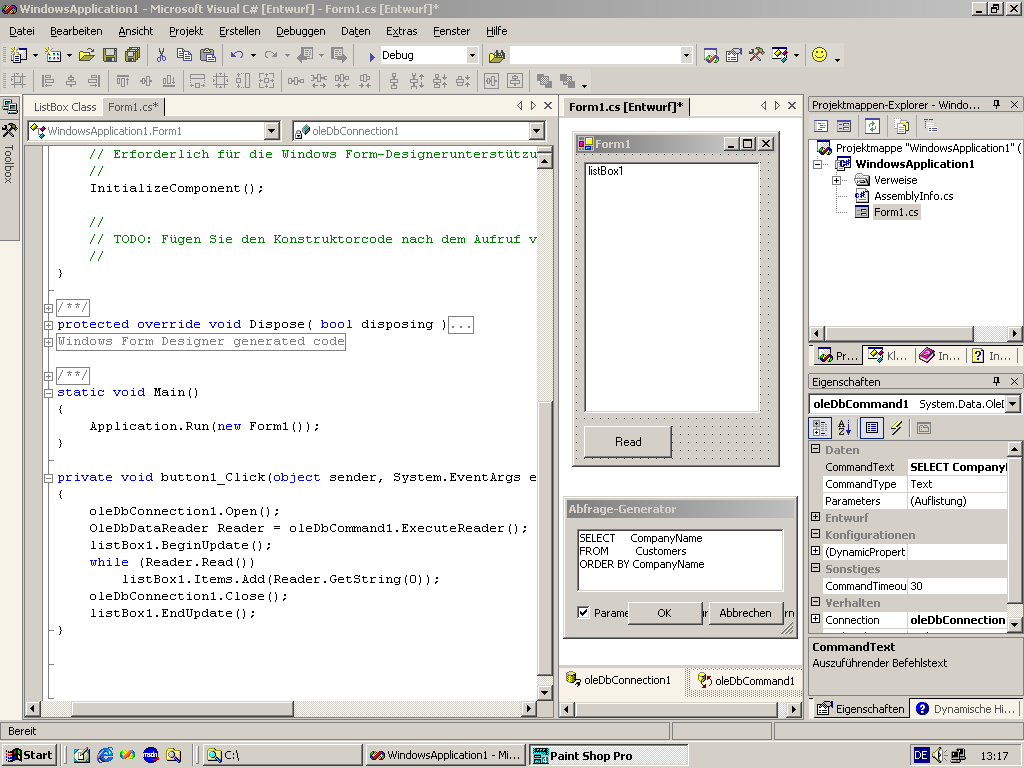
Als Beispiel dient eine denkbare einfache Anwendung,
die Datensätze aus der berühmten Nordwind-Datenbank holt und in
einen Editor einträgt (siehe Bild 3).
Bild 3: In der Entwicklungsumgebung
sieht man die Daten-Komponenten unterhalb des Formulars im Designer. Die
SQL-Anweisung gehört zur Eigenschaft CommandText des OleDbCommands.
Die Datenbankkomponenten OleDbConnection
und OleDbCommand werden in die Ablage gelegt und das DbCommand
mit der DbConnection über die Eigenschaft verbunden. Ein Klick
auf den Schalter führt das Kommando aus und generiert über
IDbCommand.ExecuteReader() ein OleDbDataReader-Objekt. Dieses
liefert in einer Schleife mit DataReader.Read()-Aufrufen alle Datensätze
der Ergebnismenge, die dann in den Editor eingetragen werden (Listing).
Mit dem Auslesen von Daten alleine ist es aber nicht
getan. ADO.NET benötigt eine Schnittstelle über die in beide Richtungen
Informationen ausgetauscht werden könne. Dies ist die Aufgabe von
DbDataAdapter. Anders als die bisher besprochenen Komponenten ist
der DbDataAdapter kein bloßes Interface sondern eine abstrakte
Basisklasse innerhalb des .NET-Frameworks. Die speziellen DbDataAdapter-Nachkommen
der einzelnen Managed Provider erben somit nicht nur die Verpflichtung,
bestimmte Methoden anzubieten sondern auch vorhandene Implementierungen.
Eine Schnittstelle IDbDataAdapter gibt es allerdings auch.
Adapter
Der DbDataAdapter besitzt zwei wesentliche
Methoden: Fill() und Update() mit denen er Daten vom Datenspeicher
zur Datenmenge hin (Fill()) und her (Update()) schaufelt. Dazu verwendet
er je ein DbCommand für das Ermitteln der Daten über
ein SELECT-Kommando, und das Modifizieren über INSERT, UPDATE und DELETE.
Zum Füllen der Datenmenge muss der Adapter mit einem DataReader
arbeiten, weil dies der einzige Weg ist, die Daten von der Datenquelle abzuholen.
Die Updates kann er direkt ausführen, indem er ein ExecuteNonQuery()
auf dem entsprechenden DbCommand-Objekt aufruft. Der Aufbau der
SQL-Befehle für den Abgleich mit der Datenquelle ist allerdings ein
eigenes Thema, auf die in einem weiteren Artikel gesondert eingegangen wird.
Damit kommen wir zur DataSet-Komponente, welche die
Datenmenge repräsentiert und wechseln damit gleichzeitig vom Managed
Provider zu den Daten-bezogenen Komponenten im .NET Framework. Das DataSet
ist der zentrale Bestandteil von ADO.NET und stellt wie schon erwähnt
eine eigenständige Speicher-basierte Datenbank für sich dar. Diese
Datenbank wird von einem oder mehreren DbDataAdaptern gefüllt,
offline bearbeitet und dann mit den selben DbDataAdaptern wieder
mit der Datenquelle synchronisiert, indem die vorgenommen Änderungen über
SQL-Befehle an den Datenspeicher geschickt werden.
Wenn man von einer vollständigen Datenbank spricht,
müssen unter anderem Tabellen, Datensätze, Spalten und Meta-Informationen
vorhanden sein. Und so wundert es nicht, dass der interne Aufbau des DataSet
recht komplex ist (Bild 4).
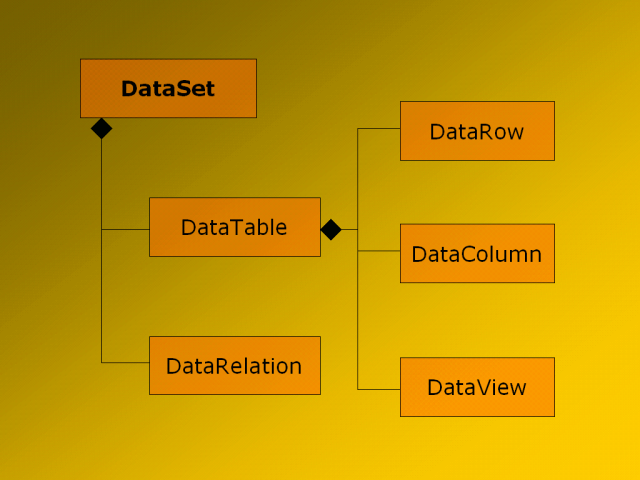
Bild 4: Ein DataSet enthält Tabellen mit
Zeilen und Spalten sowie Beziehungen zwischen Tabellen.
Es enthält eine oder mehrere Daten-Tabellen,
die wiederum aus Zeilen und Spalten aufgebaut sind. DataRow-Objekte
enthalten die Daten eines einzelnen Datensatzes, während DataColumn-Objekt
die Spalten einer Datenbank-Tabelle beschreiben. Neue Zeilen können
mit der Add()-Methode einfach zur Tabelle hinzugefügt werden,
während vorhandene Zeilen interessanterweise direkt über einen
Index angesprochen werden. Bei einer Speicher-basierten Datenbank ist das
natürlich möglich.
Das wesentlich Neue am DataSet im Vergleich
zu einem ADO RecordSet ist, dass es mehr als eine Tabelle aufnehmen
kann. Über die DataTableCollection können die einzelnen
Tabellen angesprochen werden, und es ist auch möglich, jederzeit neue
Tabellen hinzuzufügen. Wenn man möchte, kann man das DataSet
also auch völlig ohne Managed Provider als In-Memory-Datenbank betreiben.
Zwischen den Tabellen im DataSet werden auch Beziehungen in Form
von Equate Joins verwaltet. Die DataRelationCollection verwaltet
beliebig viele DataRelations, von denen jede eine Beziehung zwischen
zwei Tabellen herstellt. Die Kopplung wird dabei über die Gleichsetzung
der Werte zweier Spalten hergestellt, also nach dem Schema ORDER.Id
= ORDERDETAIL.OrderId.
An dieser Stelle muss etwas zum Thema ADO.NET und
XML gesagt werden. Die Verbindung dieser beiden Welten wurde immer wieder
sehr stark betont, vor allem solange XML das In-Thema schlechthin in der
IT-Branche war. Die Ankopplung ist zugegebenermaßen sehr elegant gelöst,
stellt sich in der Praxis jedoch als wenig spektakulär dar. Im Prinzip
geht es um die drei Methoden WriteXml(), WriteXmlSchema()
und ReadXml(), die das DataSet implementiert. Mit diesen
Methoden kann man so einfach wie effektiv aus dem Inhalt des DataSets ein
XML-Dokument generieren und umgekehrt ein beliebiges(!) XML-Dokument in
das DataSet einlesen. Beim Einlesen erzeugt das DataSet
nach vorgegebenen Regeln selbständig Daten-Tabellen, in denen die Daten
des Dokuments abgelegt werden.
Die Welt der Datenbank-fähigen Steuerelement,
als die oberste Schicht im Architekturmodell ist nicht mehr Teil von ADO.NET
und damit auch nicht Gegenstand dieses Beitrags. Im Beispiel wird ein einfaches
Datengitter benutzt, um eine Tabelle aus dem DataSet darzustellen. Auch
diesmal wird ein OleDbConnection-Objekt und ein OleDbCommand-Objekt benötigt.
Allerdings werden diese Komponenten nicht von Hand eingefügt, sondern
vom Datenadapter-Assistenten generiert. Dieser startet automatisch sobald
man die OleDbDataAdapter-Komponente in den Designer zieht. Der Assistent
unterstützt bei Auswahl des Daten-Speichers und bei der Formulierung
des SQL-Befehls für die anzuzeigende Datenmenge. Anschließend
fügt man noch ein DataSet-Objekt ein, dem automatisch der Name dataSet1
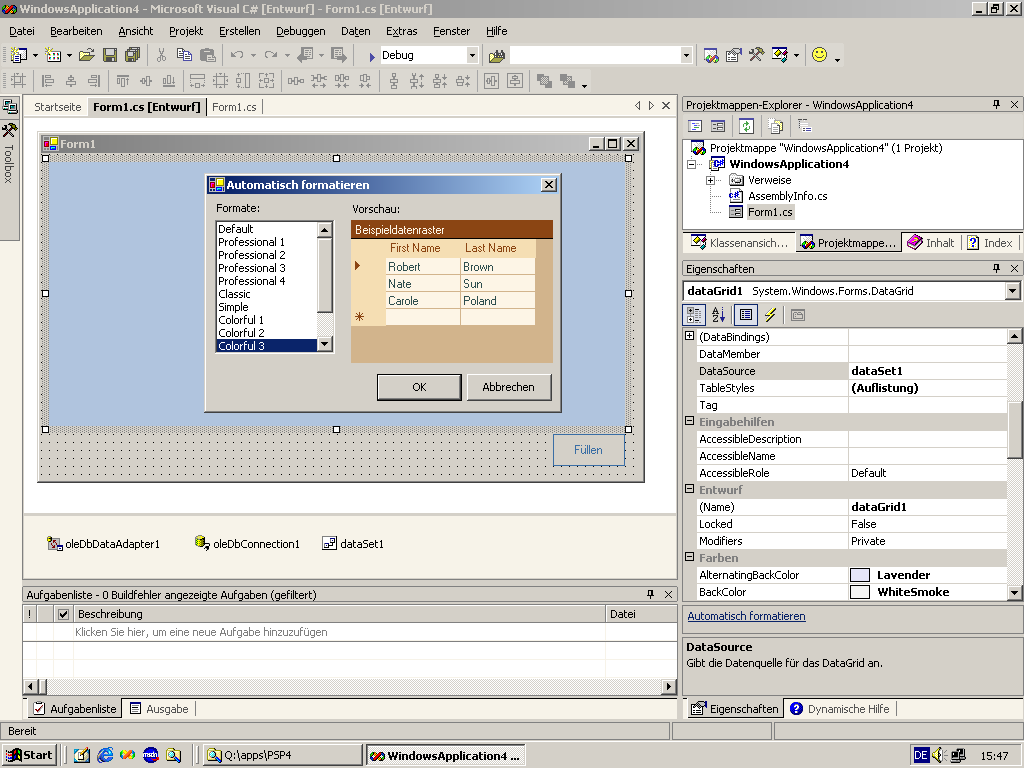
zugewiesen wird (Bild 5).
Bild 5: In diesem Beispiel
sind die DbCommand-Objekte im OleDbDataAdapter enthalten und deshalb im
Designer nicht sichtbar. Dafür sieht man das DataSet-Objekt und das
DataGrid mit dem Assistenten für die Gestaltung.
Auf dem Formular finden ein DataGrid und
ein Schalter Platz. In dessen Ereignis-Behandlungsroutine wir das DataSet über
die Methode Fill() des OleDbDataAdapters gefüllt.
Das DataGrid ist über die Eigenschaft DataSource
mit dem DataSet verbunden und zeigt somit die Ergebnismenge an
(Listing 2). Das Ergebnis nach einem Klick auf den Schalter ist in Bild
6 dargestellt.
Bild 6: Das DataGrid konfiguriert die Spalten
automatisch nach dem Inhalt im DataSet.
Pro und Kontra
Wie man sieht, hat sich auf dem Weg von ADO zu ADO.NET
einiges getan. Auch wenn einige Begriffe wieder auftauchen, so sind etliche
Konzepte doch ganz beträchtlich weiterentwickelt worden, besonders
im Vergleich mit dem ursprünglichen ADO. Wo liegen nun die entscheidenden
Vorteile des neuen Modells?
Wohl mit am Wichtigsten dürfte die bessere Skalierbarkeit
von ADO.NET-Anwendungen im Vergleich zu ADO-Anwendungen sein. In klassischen
Client/Server-Anwendungen stellt die Anzahl der gleichzeitig offenen Datenbank-Verbindungen
immer eine Obergrenze für die maximal zulässige Anzahl an Benutzern
dar. Dem versucht man mit Maßnahmen wie der Wiederverwendung von solchen
Verbindungen zu begegnen, macht damit die Anwendung aber sehr kompliziert.
In ADO.NET wird von vorne herein die unverbundene Datenmenge unterstützt
und gefördert, so dass offene Datenbankverbindungen keine große
Rolle mehr spielen. Dies ist besonders bei unternehmensweiten Anwendungen
ein entscheidender Punkt, wo über das Inter- oder Intranet etliche
zehntausend Anwender potenziell gleichzeitig auf die selbe Datenbank zugreifen.
Ein zweiter großer Fortschritt liegt darin,
dass ADO.NET endlich ein verständliches, durchgängiges und sauberes
Objektmodell anbietet. Die beteiligten Klassen und Schnittstellen sind hervorragend
entworfen und gut austariert. Die Zuständigkeiten sind klar definiert
und durch die Möglichkeit der Vererbung in .NET kann man bei eigenen
Erweiterungen von vorhandenem Code im Framework profitieren. Dadurch wird
sowohl die Implementierung von Managed Providern als auch der Einsatz des
Datenbank-Zugriffs als solchem erheblich vereinfacht. Als Ergebnis wird
das Angebot an Managed Providern schnell steigen und die Produktivität
der Entwickler wachsen. Letzteres um so mehr, als die Entwicklungsumgebung
Visual Studio.NET einige nützliche Assistenten für die Entwicklung
von ADO.NET-Komponenten und -Anwendungen enthält.
Als drittes ist die verbesserte Möglichkeit zum
Datenaustausch zu nennen, mit der ADO.NET aufwartet. Durch die wirklich
einfache Konvertierung der DataSet-Inhalte aus und nach XML-Dokumenten gibt
es nun ganz andere Voraussetzungen für einen Datenaustausch mit anderen
Anwendungen bzw. Plattformen als das mit COM der Fall war. Trotzdem müssen
potentielle Kommunikationspartner natürlich erst noch das XML-Schema
implementieren, bevor es losgehen kann. Aber der Aufbau der XML-Dokumente
aus dem DataSet ist tatächlich sehr einfach und enthält keine
der sonst von Microsoft so gerne eingesetzten proprietären Erweiterungen,
so dass die Chancen für die propagierte Zusammenarbeit tatsächlich
gar nicht so schlecht stehen.
Für die Entwickler heißt es also wieder
einmal dazulernen. Die Problemchen mit der neuen Technologie stellen sich
dann früh genug ein. Ein ganz heißer Kandidat für aufkommende
Schwierigkeiten sind Abfragen mit zu großer Ergebnismenge und Updates
von komplizierten DataSets. Während ein SELECT * FROM
MyTable auf einer Datenbank mit zehn Millionen Datensätzen zwar
nicht empfohlen wird aber dennoch möglich ist, wenn man einen Server-seitigen
Cursor verwendet, kommt das für ein unverbundenes DataSet
definitiv nicht in Frage. Der Speicherverbrauch auf der Client-Seite würde
die Anwendung schlicht zum Platzen bringen.
Andererseits wird es nicht immer einfach sein, das
passende UPDATE-Statement für Änderungen an den Daten zu finden.
Einfaches Beispiel: Wenn in der Ergebnismenge von SELECT Date, Customer
FROM Orders WHERE Date > "1/1/2001" sowohl das Datum als
auch der Kunde geändert werden, wie kann dann der Abgleich mit der
Datenquelle stattfinden? Hier wird sich so mancher den Server-seitigen Cursor
zurückwünschen.
Trotz des nötigen Lernprozesses und einiger neuer
Schwierigkeiten ist .NET im Allgemeinen und ADO.NET im besonderen, und das
ist jetzt eine persönliche Überzeugung, die Mühe mehr als
Wert. Es ist lange her, dass Microsoft den Entwicklern eine durchgängige
und klar strukturierte Plattform auf dem aktuellen Stand des Software-Engineerings
angeboten hat (gab es das schon jemals?). Diese Chance sollten wir nutzen.
Im nächsten Heft gehe ich genauer auf die Möglichkeiten
des DataSet und insbesondere die Mechanismen für die Aktualisierung
der Datenquelle ein.
Peter Pohmann, 37, ist Geschäftsführer
von dataweb, einem Softwarehaus in Niederbayern. Er ist seit über 15
Jahren als Entwickler, Fachautor, Coach, Referent und Berater für Objektorientierte
Technologien und Windows-Programmierung tätig. Er freut sich über
Feedback zu diesem und verwandten Themen an peterDOTpohmannADDdataweb.de.
Listing 1:
private void button1_Click(object sender, System.EventArgs e)
{
oleDbConnection1.Open();
OleDbDataReader Reader = oleDbCommand1.ExecuteReader();
listBox1.BeginUpdate();
while (Reader.Read())
listBox1.Items.Add(Reader.GetString(0));
oleDbConnection1.Close();
listBox1.EndUpdate();
}
Listing 2
private void button1_Click(object sender, System.EventArgs e)
{
// Öffnet Datenbank-Verbindung, führt SelectCommand
// aus, schreibt das Ergbnis in das dataSet1 und
// schließt die Verbindung wied
oleDbDataAdapter1.Fill(dataSet1);
}
|


{kind=link}
{kind=link}